知識產權代理 護航創新與市場競爭力的關鍵

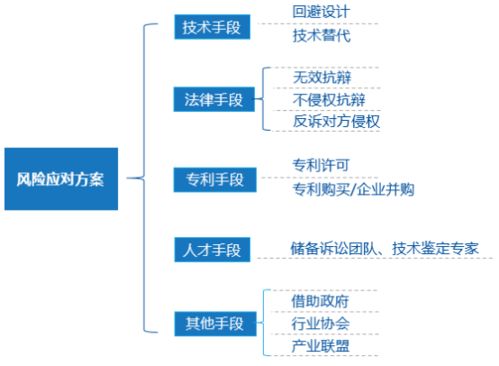
在當今知識經濟時代,知識產權已成為企業核心競爭力的重要組成部分。專利、商標、著作權等無形資產的保護和運營,直接關系到企業的創新能力和市場地位。深圳市神州聯合知識產權代理事務所憑借專業的團隊和豐富的實踐經驗,致力于為客戶提供從知識產權申請到維權的一站式服務。通過嚴謹的流程管理、法律解讀和戰略規劃,我們幫助客戶有效應對侵權風險,優化知識產權布局,并助力企業在全球化競爭中抓住先機。在深圳作為科技創新高地的背景下,我們的使命是成為企業最值得信賴的知識產權伙伴,匯聚專業智慧,推動社會創新生態的健康發展。
如若轉載,請注明出處:http://m.boyou88.cn/product/1.html
更新時間:2026-06-19 11:39:29